개념
Set / Map을 구현한 종류로 Tree와 Hash가 있는데,
어떤 것으로 구현했냐에 따라 값 추가와 탐색 방법이 상이합니다.
또한 그에 따라 구현 방법별 값 추가와 탐색의 시간 복잡도가 다릅니다.
일반적으로는 Hash가 Tree보다 더 빠르므로, 자주 사용됩니다.
Hash
Hash는 값을 저장하고 조회하는데 있어 가장 빠른 알고리즘입니다.
그 메커니즘으로는, 저장하고자 하는 값을 어떤 값과도 중복되지 않는 숫자 코드로 변환(이를 해시 코드라 지칭)하여
해당 코드의 메모리 위치에 값을 저장하는 방법입니다.
다음은 저장을 그림으로 설명한 것입니다.

따라서, 저장하려는 값을 일련의 공식을 통해 해시코드로 변환한 값이, 저장되는 위치입니다.
그렇기 때문에, 값을 조회할 경우에도 저장된 값만 알고 있다면,
해시 코드로 변환하여 그 주소 안에 어떠한 값이 저장되어 있는지 알 수 있습니다.
탐색을 그림으로 나타내자면,
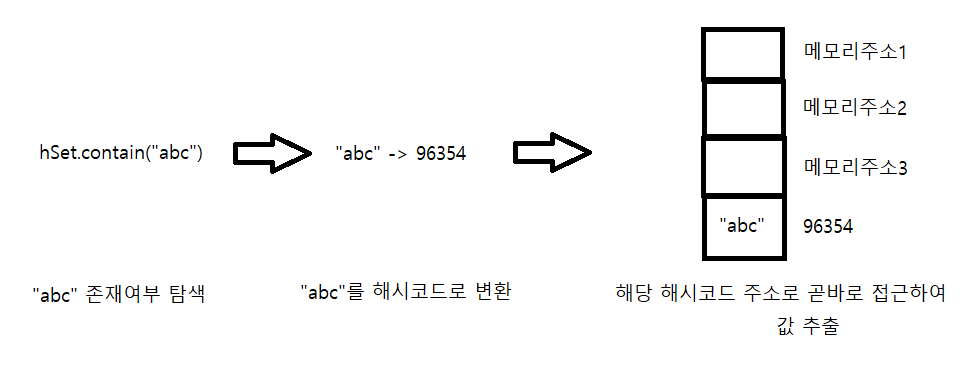
보여드린 저장과 탐색 방법에 따라, 시간 복잡도가 나옵니다.
- 저장 : O(1)
- 탐색 : O(1)
이런 식으로 값을 고유한 코드(해시코드)로 변환하여
해당 코드 위치에 값을 저장하고 조회하는 방법을 해시라고 합니다.
HashSet
위 해시의 내용대로 값을 저장한 방식이 HashSet입니다.
Set은 비선형 자료구조이기 때문에 순서되로 저장/출력이 되지 않습니다.
또한, 값의 중복을 허용하지 않고 있습니다.
해쉬의 경우 값 자체가 메모리 주소가 되기 때문에,
같은 위치에 두 개의 값을 저장할 수 없고, 한 번만 저장됩니다.
Iterator
자바의 컬렉션에 존재하는 값들을 읽어오는 방법으로 ' Iteraotor '라는 클래스가 존재합니다.
Iterator는 해당 컬렉션의 주소값을 기반으로 하나씩 값을 조회하는 클래스입니다.
대표적으로 다음과 같은 두 개의 함수가 존재합니다.
hasNext() : 다음 값을 가지고 있는지 true/false 반환
next() : 다음 값으로 이동 및 반환
각각의 컬렉션은 Iterator를 반환하는 함수를 갖고 있고,
이 함수는 컬렉션의 첫 번째 주소 값을 반환하는 형식으로 되어있습니다.
Iterator를 이용해 컬렉션을 추출하는 방법은
첫 번째 주소를 담은 Iterator 생성 -> 반복문을 통해 하나씩 이동하며 저장된 값 반환 입니다.
Iterator<String> setIter = hSet.iterator(); // 만든 hSet의 iterator 정보를 담은 setIter 변수 생성(hSet 자료형과 동일하게 생성)
while(setIter.hasNext()) { // 값이 존재할때까지 반복
String str1 = setIter.next(); // hSet의 다음 값 가져오기
System.out.print(str1 + " "); // 출력
}
Tree
TreeSet에 사용되는 트리의 종류는 이진트리 기반의 레드 · 블랙트리입니다.
단순히 자식 노드가 최대 2개가 될 수 있는 이진 트리 개념에 더하여,
한 노드를 기준으로 적은 값은 왼쪽에, 큰 값은 오른족에 저장하는 개념을 추가한 것이 레드 · 블랙트리입니다.
다음은 이진트리와 레드 · 블랙트리를 비교한 그림입니다.

기능 및 사용 방법
HashSet, TreeSet은 구현 및 저장, 조회 방법만 다를 뿐 사용하는 방법은 동일합니다.
단, 시간 복잡도는 구현의 차이로 인해 차이가 있습니다.
- 저장 : O(log n)
- 탐색 : O(log n)
'Algorithm & Data Structure > Data Structure' 카테고리의 다른 글
| [자료구조] Map 출력 (keySet, entrySet, Iterator) (0) | 2021.11.02 |
|---|